列联表是医学研究中最常见的数据存储格式(或数据类型)之一。
通常,列联表的水平和垂直方向显示两个不同的类别变量,最常见的类型是四网格表(即2×2列联表)。 如下图所示,水平变量是“是否患有肺癌”,纵向变量是“是否吸烟”,两者都是二元分类变量。 表中的数据显示了每个calcategories变量的水平组合下的人数(频率)。
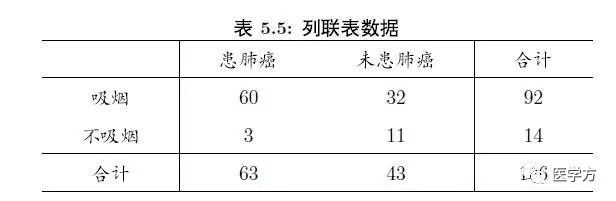
这是最简单的列联表数据,也是大家最熟悉的。 当然,在现实世界中,列联表的数据格式不止一种。 我们来一一熟悉一下,顺便学习一下如何对数据进行统计检验。
拟合优度检验
拟合优度检验针对的是样本数据的分布情况,即样本数据的分布是否与已知总体的分布相同。

现在我想研究男性人群中所有血型的比例是否相同。

从卡方检验的结果可以看出,四种血型在男性中的分布并不均匀。
如果提前知道男性人群中四种血型的分布,是否想测试样本是否符合分布?

这里的参数p定义了已知总体的频率分布。
卡方均匀性检验和卡方独立性检验
卡方同质性检验用于比较不同群体下各血型的比例是否一致,即男性和女性群体中血型分布是否相同。

上述结果表明,男女群体之间的血型分布没有显着的统计学差异。
独立性检验的结果也是一样,检验的是血型分布是否与性别变量相关。
Cochran-Mantel-Haenszel 卡方检验
CMH 检验用于检验分层分类变量血型配对表图,因为它是分层的,即至少是三维数据。 数据的每个维度至少包含2个级别。 另外方法推荐 :不要对列联表那么愚蠢。,对于行变量无序、列变量有序的数据,由于层次关系不能忽略,只能使用CMH检验血型配对表图,而不能使用Pearson卡方检验。
例如,对于以下数据:


这个数组分为三个维度,分层变量是青霉素的级别,一共5个级别(按顺序递增),另外两个变量是是否延迟(延迟)注射,结局(治愈还是死亡)。
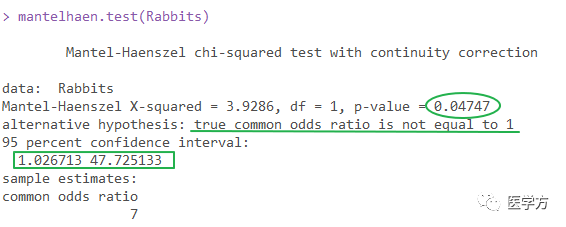
CMH检验结果显示P值小于0.05,因此检验有统计学意义,OR=7,95%CI为1.027、47.725,如何解释?
也就是说,青霉素分层后,立即注射(延迟=无)和延迟注射(延迟=1.5h)治愈率的OR值为7。这个是合并的OR值,与粗略的比较OR,即不分层的OR。 如果差异较大,则表明青霉素是混杂因素。 如果青霉素水平与结果之间存在交互作用,则该方法也是可行的,但如果存在三维交互作用方法推荐 :不要对列联表那么愚蠢。,则该方法不适用。
对于序数分类数据:
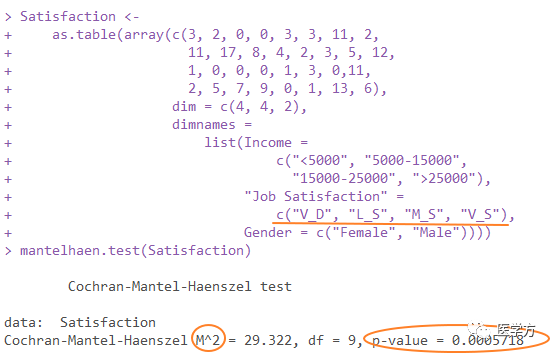
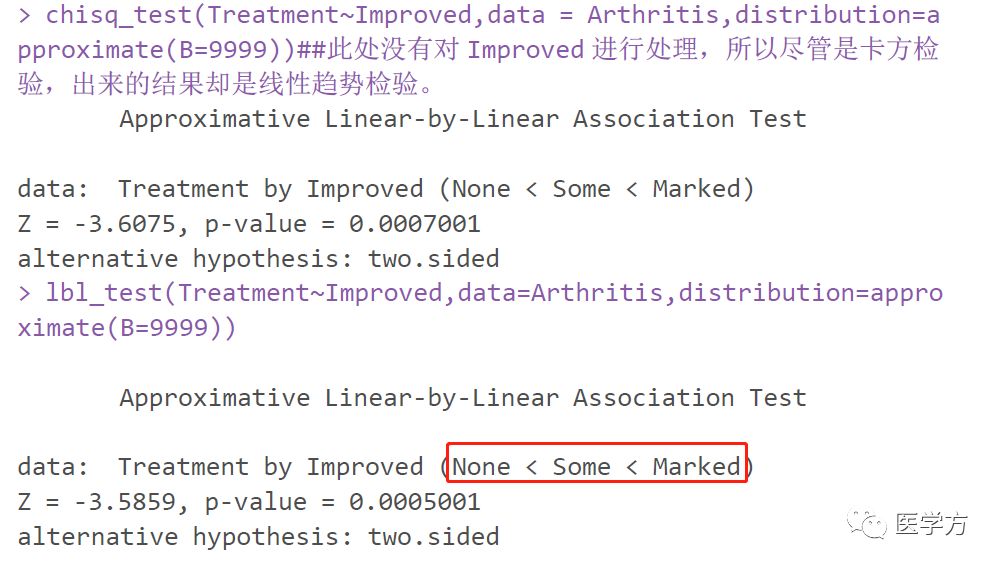
如图所示,工作满意度是一个四类变量,薪资水平也可以看作是一个四类变量。 最终P值小于0.05。 可以得出结论,随着工资的增加,工作满意度也会增加。 如果使用一般的皮尔逊X2检验,只能比较不同工资水平下对工作满意的人数构成比例是否相同。
配对四表卡方检验
配对四面板表常用于“前后自我比较”实验设计,也常用于“筛选”实验。

从p值可以看出,病例与对照之间存在统计学上的显着差异。 在这种情况下,如果你想检查行和列变量之间的相关性,你仍然使用 chisq.test()。
序数分类变量的列联表测试
序数分类数据是指在R×C列联表中,行变量或列变量是序数分类,或者两者都是序数分类。 如果分组变量(行变量)为有序分类数据,而列变量为无序分类数据,则直接将其视为R×C无序分类数据进行分析。 行变量是无序分类血型配对表图,列变量(指标变量)是有序变量,比如药品的疗效、群众的满意度等。 这种数据可以通过wilcox来测试。 对于既有序又分类的数据,此时如果行列变量属性相同,则相当于配对四表数据的扩展。 如果行和列变量的属性不同,则可以推断两个变量之间是否存在相关性方法推荐 :不要对列联表那么愚蠢。,也可以推断该相关性是否是线性的。 前者使用 chisq.test(),后者可以使用 lbl_test()(来自 coin 包)。
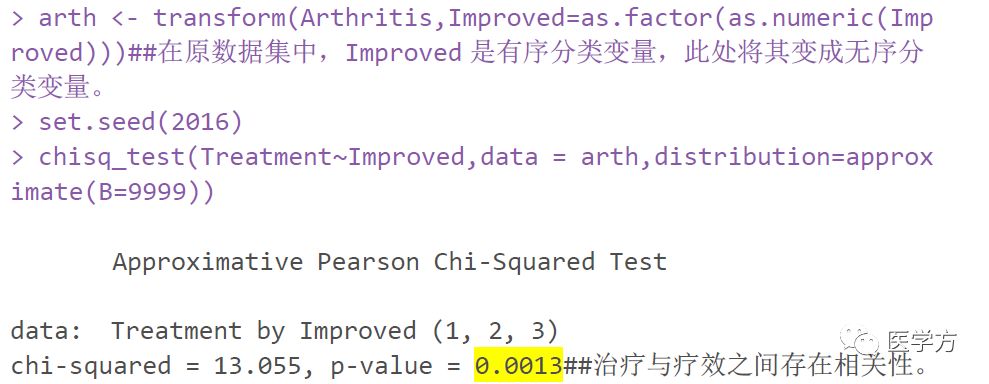
”
 标签:
无标签
标签:
无标签
版权说明:以上内容来自网友投稿,若有侵权请联系
★文章来自爱算卦网,未经允许不得转载!★











